

Unmasking Data Leaks: A Guide to Finding, Fixing, and Preventing
Jordan Wright June 20th, 2019 (Last Updated: June 20th, 2019)00. Introduction
A couple of weeks ago, I had a blast speaking at my local BSides San Antonio. For my talk, Unmasking Data Leaks: A Guide to Finding, Fixing, and Preventing (slides), I wanted to show that security research, like the kind we do here at Duo Labs, can be accessible to anyone.

To demonstrate this, I showed how researchers are able to discover data leaks caused by leaving exposed databases on the Internet. I talked through the process, live-coded a system for doing this on stage, and then talked about how to prevent data leaks from occurring in the first place.
While the talk was recorded and should be released soon, I wanted to summarize things in this post, as well as give some lessons I learned.
01. How We Do Security Research
I plan to write more about our research process in future posts, but for now it's fair to say that our research process follows three steps: identifying a problem, exploring the problem, and recommending solutions.

When performing research, we follow our motto of "Disrupt. Derisk. Democratize." This motto can fill an entire post, but at a high-level we want our research to move our industry forward, derisk potential solutions and, arguably most important, democratize our work to the wider industry. When we present our work, the goal is to start a conversation, sharing how we got our results and encouraging other researchers to expand on the work, taking it to the next level.
Let's see this in action when exploring data leaks.
02. Diving into Data Leaks
Identifying the Problem
There have been numerous reported instances of large scale data leaks caused by misconfigured databases left online. Back in 2016, I presented a talk at Lascon called "Scanning IPv4 For Free Data and Free Shells" (slides) where I presented the results of a research project where we studied this exposure at scale across multiple database types.
With an instance of exposed information reported the day before the conference, it's clear that data leaks are still a problem worth exploring.
Exploring the Problem
While the Lascon talk covered the results of my work, for this talk I wanted to talk more about how the research was performed.
To discover open databases, we have a couple of options. The first option is to run a port scan across the entire IPv4 space for services that respond to a known database port. For example, when looking for Elasticsearch instances, we would scan for TCP port 9200.
Once we have a list of hosts exposing a particular database (in this case Elasticsearch) to the Internet, we can use an official client to get more information about the data hosted in that database. For example, we might ask for the database name (e.g. users) and field names (e.g. username and password), so as to determine if there is sensitive information being stored without viewing the actual data itself- even though it's publicly available.
It can take a fair bit of time to run such a large port scan even with tools like ZMap or masscan, so instead we can take a different approach. There are service providers such as Censys, Shodan, or BinaryEdge which regularly scan the IPv4 space for common ports and services, exposing this dataset via an API.
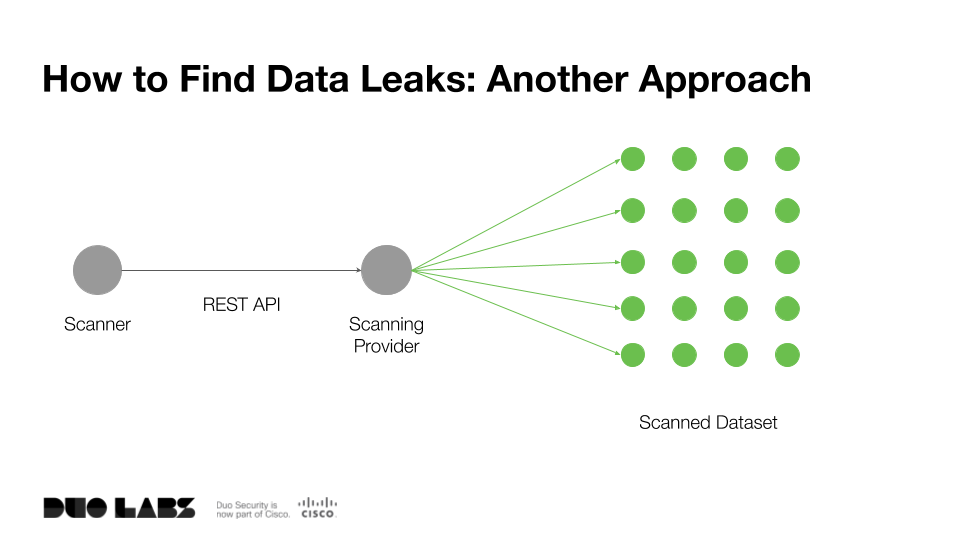
For this talk, I opted to use Censys to gather a list of exposed Elasticsearch instances. The free plan allowed us to retrieve a dataset of 1,000 hosts running Elasticsearch (out of a claimed total of about 25,000 hosts). This gave a game plan for the scanner I wanted to build live during the talk:

Specifically, I wanted to gather a list of exposed Elasticsearch instances, then use the Python Elasticsearch client to gather the indexes, properties, and number of documents stored in each instance, storing everything in a CSV for further searching.
A Note on Live-Coding
To show that this type of research is accessible to everyone, at this point in the talk I opted to live-code much of the scanning system on stage. Coding something on stage in front of dozens of people was terriying to me. Things started off great, but towards the end of the process, I kept getting random syntax and logic errors to the point where, for the sake of time, I opted to fallback to the known-good version I made before the conference.
It turns out the final error was simply the result of me passing a string to a function when I should have passed a list.
While things didn't go perfectly (far from it!) I'm still glad I took the risk. It showed that research doesn't always go as planned, and that there will always be challenges to work through along the way, though hopefully not in front of a live audience! It's also a good reminder to have a backup plan for live demos.
You can find the final code used on Github.
What We Found
With our dataset in hand, we can start searching for potential data leaks. To find hosts potentially exposing sensitive information, we can use grep looking for property names that might be sensitive, such as password:
grep -i password elasticsearch_instances.csv| wc -l
61
Or potentially token to look for API or OAuth tokens:
grep -i token elasticsearch_instances.csv | wc -l
400
In addition to sensitive information, we can identify patterns of activity. When searching through the dataset we noticed a mapping called howtogetmydataback appearing on approximately 15% of the hosts:
grep howtogetmydataback elasticsearch_instances.csv | wc -l
149
Each of these records contain properties similar to contact, bitcoin_address, and message:
ip_address,index,mapping,fields,num_records
x.x.x.x,readme,howtogetmydataback,"['contact', 'bitcoin_address', 'message']",1
This indicates that attackers connected the Elasticsearch service, removed the stored data, and left a ransom note on how to get the data back. This is a similar pattern to the ransoms performed a while back. And this isn't the first time we've seen ransom attempts on datastores. Back in 2016 we saw similar activity with over 18,000 Redis instances being hit by ransom attempts.
03. Recommending Solutions
The last part of the talk discussed how to prevent data leaks from occurring. The root cause of data leaks is misconfigured databases (e.g. no authentication) exposed to the Internet. When many of these databases were created, this was the default configuration. Fortunately, things are changing where the software is more secure by default.
While this is a step in the right direction, there are still things administrators can do to better secure their databases. At a high-level, it's recommended to:
- Limit connections only to the required clients
- Implement authentication (and optionally RBAC), where available
- Keep your database instances up-to-date.
- Disable unneeded features, where possible
For specific recommendations on how to secure databases, here is a list of the security guides each has published:
04. Thanks, BSides SATX!
Every year I have a blast at BSides SATX. It's always a great opportunity to catch-up with old friends and meet new people in the San Antonio infosec community.
I enjoyed the opportunity to speak, and hope that I made the work we do a little more accessible to people along the way. With all of the research we do, the goal is to start a conversation. We love seeing researchers read our work, expand it, and take it to the next level. If you're interested in this type of work, please don't hesitate to reach out! We'd love to hear from you.