

Debugging Apache Spark pipelines
Stefano Meschiari July 2nd, 2019 (Last Updated: July 2nd, 2019)00. Introduction
Apache Spark has become the engine of choice for processing massive amounts of data in a distributed fashion. The machine learning pipeline that powers Duo's UEBA uses Spark on AWS Elastic MapReduce (EMR) to process authentication data, build model features, train custom models, and assign threat scores to incoming authentications.
Spark abstracts away a lot of the complexity involved in optimizing, scheduling, and executing data transformations. However, in our experience, there’s still a lot of effort involved on the part of the implementer to build a solution that will be robust in different scenarios. Because there are many types of applications and data workloads, and Spark offers a wide array of tuning parameters, settling on a robust and broadly applicable configuration is somewhat of an art — an art that is problem- and scale-dependent (although there have been attempts to automate this process).
Excellent guides on Spark configuration and tuning are available, and we included some of those resources in the Resources section of this guide. Even so, we found that there is also a lot of material that is effectively outdated (due to large shifts of the Spark platform between 1.x and 2.x, and the introduction of new, incompatible APIs) or misleading (recipes that might have worked on a specific problem are not necessarily widely applicable).
In this guide, we will detail some of the practical pitfalls we encountered while building our data pipeline using Spark 2.3 running on AWS EMR, and the concrete solutions that helped overcoming those hurdles. We will keep this guide updated with new content as we learn new debugging techniques.
01. Why use Spark?
There are multiple reasons for its popularity among data scientists and data engineers, including:
- relative ease of getting up and running by simply provisioning a cluster on one of the many cloud-based platforms (e.g. AWS, Google Cloud Platform, Databricks, Azure, etc.).
- familiarity with the (DataFrame)[https://spark.apache.org/docs/latest/sql-programming-guide.html] abstraction. The API is very approachable for data scientists that are used to manipulating data using SQL queries or dataframe-like transformations (e.g. Pandas, base R, dplyr, etc.)
- support for multiple languages. Although Scala is arguably the "happy path" for interfacing with Spark, the APIs are available from high-level languages such as Python and R, which are more familiar to the typical data scientist.
- the stack covers multiple use cases (including machine learning, streaming, and graphs) within a coherent ecosystem.
If you haven't used Spark yet, you can play with it interactively within a notebook environment using one of these Docker images:
docker pull apache/zeppelin # Notebook environment: Zeppelin
docker pull jupyter/all-spark-notebook # Notebook environment: Jupyter
You could also give it a quick spin using the guided tutorial in this Spark workshop.
02. Spark Web UI: The one-stop-shop
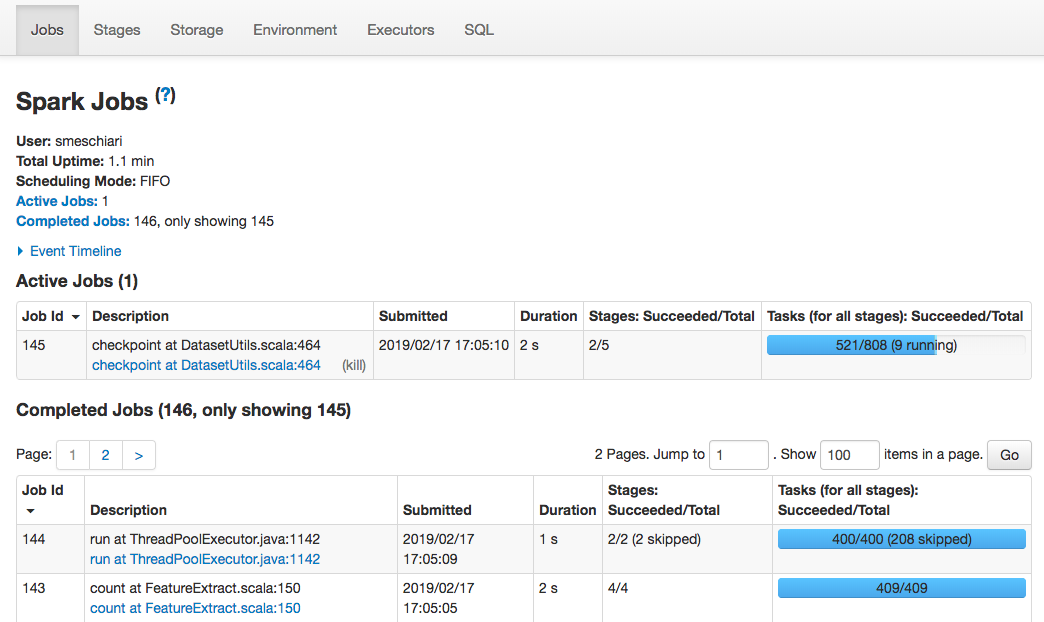
By default, Spark serves a web app that can be used to inspect the currently running Spark application, called the Spark UI. The Spark UI offers a variety of tools to help you:
- understand the performance characteristics and bottlenecks of the various intermediate data transformations;
- inspect running queries and how they are distributed to executors;
- debug failed operations.
To view the Spark Web UI:
- When running locally, the web UI is typically accessible at http://localhost:4040
- When running on EMR, you can create an SSH tunnel to access the Web UI port.
- When running in a Databricks notebook environment, the UI is accessible by clicking on the notebook's Cluster menu and clicking on
View Spark UI.
Stages

The Stages tab provides tools to inspect the the transformation graph that builds an intermediate dataset or RDD, and how each stage is broken up into tasks.
Executors
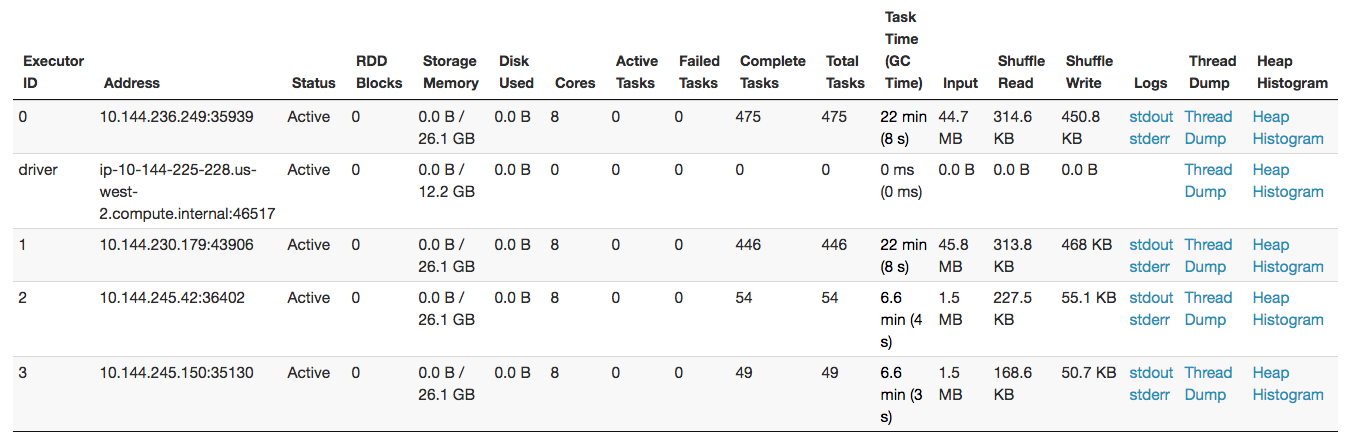
The Executors tab shows the currently running executors. For each executor, it is possible to view exactly what code each thread on the executor is executing by clicking Thread Dump. Threads executing computations are called Executor tasks in the table.
SQL
The SQL tab shows any currently executing SQL-like operation. The graph shows useful information about partition sizes and how many rows are flowing through each operation.
Storage
The Storage tab is useful to inspect how many partitions of a dataset have been cached on the executors.
03. Configuring Spark
Spark ships with sensible defaults for a vast array of tuning parameters. The default values, however, are not appropriate for all situations. Optimal values depend on the data transformations involved, data size, distributional skews, locality requirements, the sizes of the cluster nodes, the type of storage, and more. The Tuning Guide is a good starting place to inventory the basic parameters that will need to be configured in most cases.
You can view the current configuration of your Spark application using the Environment tab of the Web UI.
Defaults can be overridden in a variety of ways.
- At initialization time, when a Spark session is created
- From the command line, by passing additional command line parameters to
spark-submit. For instance, the command below setsexecutor-memoryto 10g anddriver-memoryto 8g. The most important configuration options are passed as command-line parameters (e.g.—driver-memoryor--num-executors; seespark-submit --helpfor a full list); the remaining parameters are passed as key-value combinations through multiple--confarguments (e.g.--conf "spark.network.timeout=1000s").
/usr/bin/spark-submit --conf "spark.network.timeout=1000s" --num-executors 4 --driver-memory 8g --executor-memory 10g /home/hadoop/spark_app.py
- Using the cloud platform's job configuration facilities (e.g. configuring Spark for EMR)
04. Common tuning tasks
Memory
driver-memoryandexecutor-memoryset the memory available for the driver (the main node that runs the application code) and for the executors (the core nodes that run Spark jobs). The memory available for executors is given byec2_node_memory - spark.yarn.executor.memoryOverhead - os_overhead, typically working out to about 70% of the executor nodes' memory. The higher available, the better. The executor memory requirement will impact how many executors can fit on a worker node (e.g. if an executor is set to use all memory on a worker node, only one executor will be allocated per node).spark.yarn.executor.memoryOverheadis a safety parameter that takes into account the overhead caused by the Yarn container and the JVM.
Parallelism and Partitioning
The number of partitions in which a Dataset is split into depends on the underlying partitioning of the data on disk, unless repartition/coalesce are called, or the data has been aggregated or joined. Increasing the number of partitions can increase parallelism and reduce the working set size of each executor, but causes data to be shuffled across nodes. The number of partitions can also determine the number and layout of part-files written to disk.
- For Dataset operations that cause data shuffling (joins or aggregations), Spark partitions the data into
spark.sql.shuffle.partitionspartitions (default 200). Increasing this parameter increases parallelism and can help avoid out of memory (OOM) errors. - When the data is large, this parameter should be increased. In our pipeline, we typically use a higher number than the default. The exact number is workload-dependent, but we typically get better performance and more robust execution with thousands of partitions.
- When the data set is expect to be small, or is broken into smaller datasets often (for instance, because operations are executed on filtered data subsets in a loop), this parameter should be left to default value.
executor-coresdetermines how many cores are used by each executor. This determines the number of tasks run in parallel by each executor.spark.dynamicAllocation.enableddetermines whether executors are allocated dynamically depending on the number of outstanding tasks, or if there should be a fixed number set bynum-executors. Dynamic allocation is more useful if the cluster is used by multiple Spark jobs, since it releases resources when not in use.
Maximum number of failures
When running Spark jobs, a number of issues can arise. Spark can recover from some of those issues by stopping the task and/or killing one of the executor containers, spawning a new executor, and recomputing lost data by following the execution plan and using data replicas if needed. It is a common occurrence for a small subset of the tasks making up a Spark job to fail on first run, but to complete on second run. Common issues that are recoverable include EMR nodes dying, partial HDFS corruption and lost data blocks, and too-optimistic allocation of resources by Spark.
When a given task fails more than 4 times (this value can be customized through the spark.task.maxFailures parameter), Spark assumes that the task cannot be completed and that there is some issue at a fundamental level that prevents the task from being executed correctly. This can be an actual error in the code that causes a task to fail, or it can be due to incorrect setup of Spark for the problem at hand.
Network
spark.network.timeoutsets a global timeout for network-related operations. If Spark drops executors because it is not able to get results within the timeout, it can be useful to try increasing the timeout.
05. Common issues
Below, we list some of the common issues we encountered during development.
Out of memory
Problem: A Spark pipeline fails with log messages that include strings such as Container killed by YARN for exceeding memory limits..
Solution: This is typically caused by an executor trying to allocate an excessive amount of memory. Solutions include:
- Increasing the amount of memory available on each worker node by switching to a higher-memory instance size.
- Increasing the number of partitions.
- Increasing
executor-memoryto increase the memory available to each executor, and increasingspark.yarn.executor.memoryOverheadto help Spark better predict YARN overhead. This might have the side effect of allocating fewer executors on the node, thus reducing parallelism. - While testing a PySpark application, we found that it is beneficial to reduce the number of cores used by executors (
executor-cores) so that fewer tasks are running in parallel inside the same executor. While this reduces parallelism, it increased the amount of memory available to each task enough to make it possible to complete the job.
Out of virtual memory
Problem: A Spark pipeline fails with log messages that include strings such as Container killed by YARN for exceeding virtual memory limits.
Solution: YARN is very strict in enforcing limits on the amount of virtual memory allocated. On EMR, this can be fixed by adding the following YARN property to the EMR configuration:
"Configurations": [
{
"Classification": "yarn-site",
"Properties": {
yarn.nodemanager.vmem-check-enabled": "false
}
}
],
without repercussions on the actual running of Spark jobs.
Driver out of memory
Problem: Spark fails with errors related to driver memory. Log messages include Results bigger than spark.driver.maxResultSize.
Solution:
- Ensure that you are not collecting results on the driver that are too large to fit in the driver's memory. If possible, wrap results in a Dataset instead and write them to disk (broken into partitions as needed), so that Spark does not have to collect them into memory.
- If the execution plan is too large (a typical situation was a data transformation that included multiple
filter(),join(), andunion()), Spark can throw this error even if the dataset is not collected. If possible, either recast the transformation in a way that simplifies the execution plan, or use an intermediatecheckpoint()to break up the plan into smaller chunks.
A small number of stages dominate runtime for a job (data skew)
Problem: A Spark job is stuck on completing a handful of stages.
Solution: This is typically indicative of strong data skew, manifesting itself during slow joins. If a single logical partition is much larger than the others, the data skew might make it harder to distribute and run computations in parallel. This post details the underlying reasons causing this issue. In some cases, increasing parallelism by increasing the number of partitions (with repartition() and increasing spark.sql.shuffle.partitions) and cores (spark.executor.cores) is sufficient, but more often, it will be necessary to modify the underlying data or the data transformation to rebalance the size of the partitions involved.
In the case of our pipeline, we found that a slowdown during model feature extraction originated in a specific window operation that worked on data partitioned by the user initiating an authentication. The size distribution of the user windows was skewed to the point that the query would either not complete, or would take a much longer time than anticipated to complete. We discovered that the data skew was caused by automated processes that were, in some cases, generating massive amounts of regularly spaced authentications compared to real, human users. Because the data from the automated processes was irrelevant to our models, we filtered out those partitions, resulting in a >16x speedup of our feature extraction code.
Slow writing to S3
Problem: Spark writes to a temporary location in S3 ({destination}/_temporary), then moves part-files to the final destination. This move operation is very slow, which means that some jobs can appear to be stuck, while waiting on the move to complete.
Solution: Writing to HDFS, then copying from HDFS to S3 using s3-dist-cp appears to reduce the time spent writing to S3 by an order of magnitude (we observed jobs that took > 6 hours to complete when writing directly to S3, but less than 20 minutes when doing HDFS to S3). This can be done by writing data to HDFS first, then using s3-dist-cp to copy/move to S3.
Executor connections dropped
Problem: A Spark job fails unexpectedly. Log messages include Connection reset by peer.
Solution: Try increasing the network timeout (spark.network.timeout).
Avoiding writing partition files that are too large
Problem: Spark writes one file per partition by default. Large partition sizes can cause issues when later read by differently-configured pipelines.
Solution: Set the maxRecordsPerFile option to specify the maximum number of records written per file. This parameter can be set as an option with the DataFrameWriter API, or using the Spark configuration object (spark.conf.set("spark.sql.files.maxRecordsPerFile", N)).