


Protecting Accounts from Credential Stuffing
Jordan Wright and Nick Mooney March 10th, 2020 (Last Updated: March 10th, 2020)00. Introduction
At USENIX Security 2019, researchers from Google and Stanford presented their paper, Protecting accounts from credential stuffing with password breach alerting (video), which details how they help users safely identify when their credentials have been seen in a previous breach.
This experiment started as a Chrome extension called Password Checkup which gained 650,000 users in nearly 20 days. It was recently announced that the functionality is being integrated directly into Chrome. You can find the source code here, if you’re interested.
The approach taken by the researchers has some unique, fascinating properties. Combined with the reach the technology now has, it's worth taking the time to talk about how it works. In this post, we'll give a quick background on credential stuffing, the shortcomings of existing solutions, and why Google's approach raises the bar.
01. What is Credential Stuffing?
When credentials are stolen through a database breach, malware, or some other means, they are often saved as a list by attackers. Many of these lists are publicly available and shared privately amongst attackers. It's often the case that attackers will combine lists from different sources into a single, large set of credentials called a combo list.
Credential stuffing is the act of testing all of the credentials in a combo list against websites searching for password reuse.
While the act of credential stuffing has likely been around for quite some time, large credential collections being made public over the last few years is making it easier for attackers to start participating in credential stuffing for very low effort.
02. The Current Solutions Aren't Working
The benefits of having organizations collect these datasets are two-fold: First, it helps them identify existing accounts which may be using the same credentials found in previous breaches, leaving the account susceptible to credential stuffing.
Second, it helps prevent users from using breached credentials in the future. By hooking into registration and password reset flows, you can ensure that users aren't trying to reuse credentials that are known to have been breached in the past.
While the impact of breached credentials affects every organization, not every organization has the means to actively collect, aggregate, and leverage credential datasets. This led to the rise of both free and commercial services which collect breached credentials and make them available for querying. Before discussing how the new approach presented in the paper works, it helps to understand why the existing landscape doesn't meet requirements set forth by the authors.
The paper evaluates two popular services, HaveIBeenPwned and PasswordPing, against an ideal design and threat model. Each of these services has multiple ways to create queries, whether it's submitting the username (or username hash), the password (or the full or partial password hash), or the email domain.
From a design perspective, the authors point out that the results of these services needs to be actionable, trigger only when both the complete credentials (e.g. the username and password) are found to be breached, and provided in near real-time. For example, from a service provider's perspective it's hard to know if we should prevent a username and password from being used if we only know that their username was seen in a previous breach or that this particular password was seen in a previous breach. This means we need a way to verify both the username and associated password in a safe way.
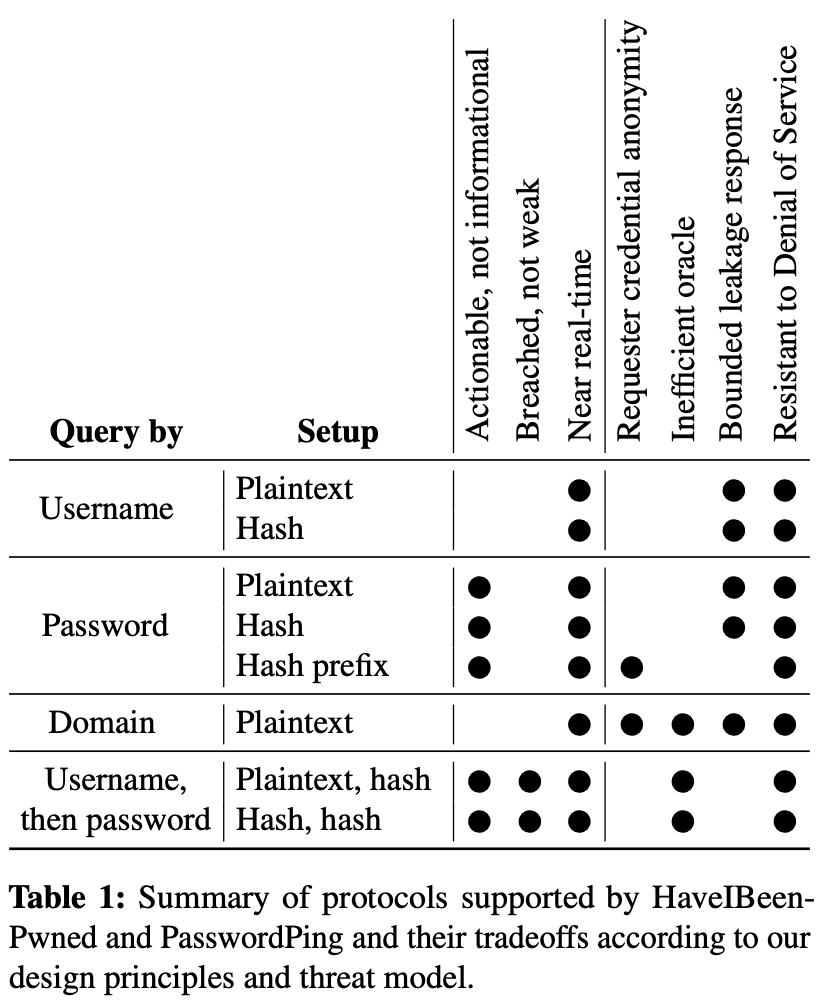
(Image Source: Thomas et al., 2019)
Next, the authors took care to design the service to protect against both a malicious client trying to learn about what credentials stored by the server, as well as malicious servers attempting to learn the credentials sent by the client.
With these requirements set, let's walk through the solution proposed by the authors.
03. Raising the Bar
The key to Google's proposed solution is a technique called private set intersection. The idea is that two parties can figure out which data they have in common without revealing anything about the data they don't.
Last year, Google released a blog post in which they give a great background on private set intersection and more. They also open-sourced the library they created to do these operations, which is used by the compromised credential detection implementation.
The way it works is like this:
1. Create the Compromised Credential Database
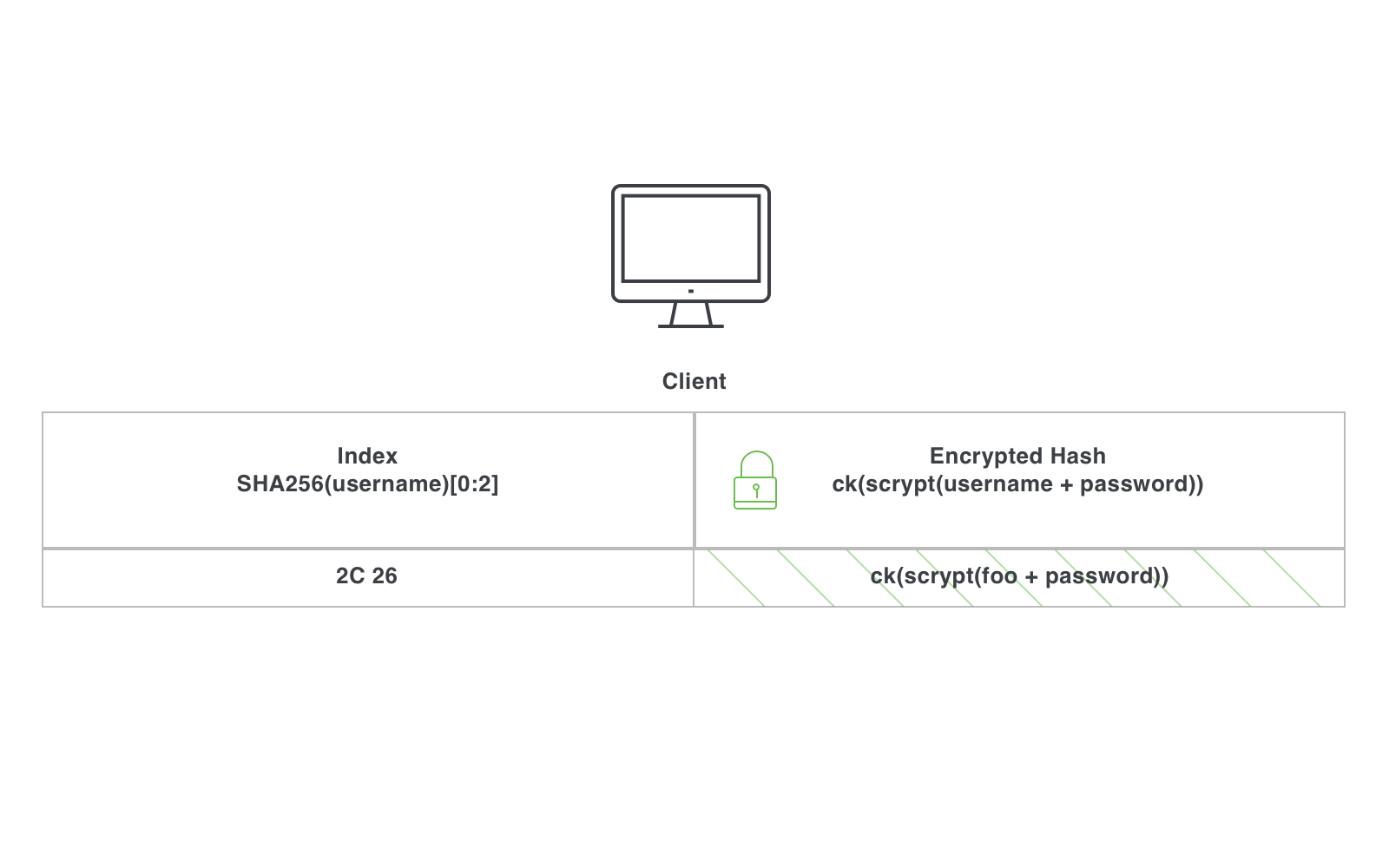
As the service provider (in this case, Google) obtains new breached credential datasets, the first thing it does is normalize each username by converting it to lowercase, removing any periods, and removing the email domain (everything after the “@”).
It then hashes each username using SHA256. The server saves the first 2 bytes of each username hash* to use as an index (more on this later). The server then hashes each credential in the dataset using scrypt**, then encrypts each of these credential hashes using a key it controls. We'll call it sk, for "server key".
What's With the 2-Byte Prefix?
In a traditional private set intersection approach where we want full anonymity, the server would provide its entire encrypted dataset to the client. The problem is that compromised credential datasets grow to include billions of credentials. It's not feasible for desktop (or especially mobile!) devices to download this entire dataset everytime they want to check to see if a credential has been breached.
That's why Google treated this like a k-anonymity problem. That is, the server splits the dataset into buckets based on some small amount of data received by the client. The server can then return just those matching records. This significantly reduces the amount of data that needs to be transferred at the cost of some client anonymity.
In this case, the authors determined that sharing just 2 bytes of a username hash worked to give back a big enough dataset to be anonymous enough, while returning data that clients can handle - roughly 2MB.
At the end of this process, the server has a dataset that looks like this:

2. Check A Credential
When the user attempts to register or login to a website, Chrome (or any client) saves the first two bytes of the hash of the normalized username. It then takes the username and password and hashes it using scrypt. It's worth noting that scrypt is used as the hashing algorithm because it is slow. This makes it hard for a malicious client to make a bunch of queries to the server with arbitrary usernames and passwords.
The client then generates a new key (we'll call it ck) and encrypts the hash with this key. The encryption method first takes the hash and maps it to a point on an elliptic curve, and then raises this point to the exponent ck. This is a special form of encryption via elliptic curves. Taking this approach gives us an interesting property: on an elliptic curve, if we have some point p, we can share out p^ck without concern about the original p or ck values being discovered. We can also compute (p^ck)^(ck^-1) to recover the original p value. This can be used to “blind” a value so that the recipient can't view it, allow it to undergo some transformation, and “unblind” it later.
This is where the magic of private set intersection comes in. The client then takes this 2-byte prefix of the hashed username and the encrypted hash of the credentials and sends it to the server.
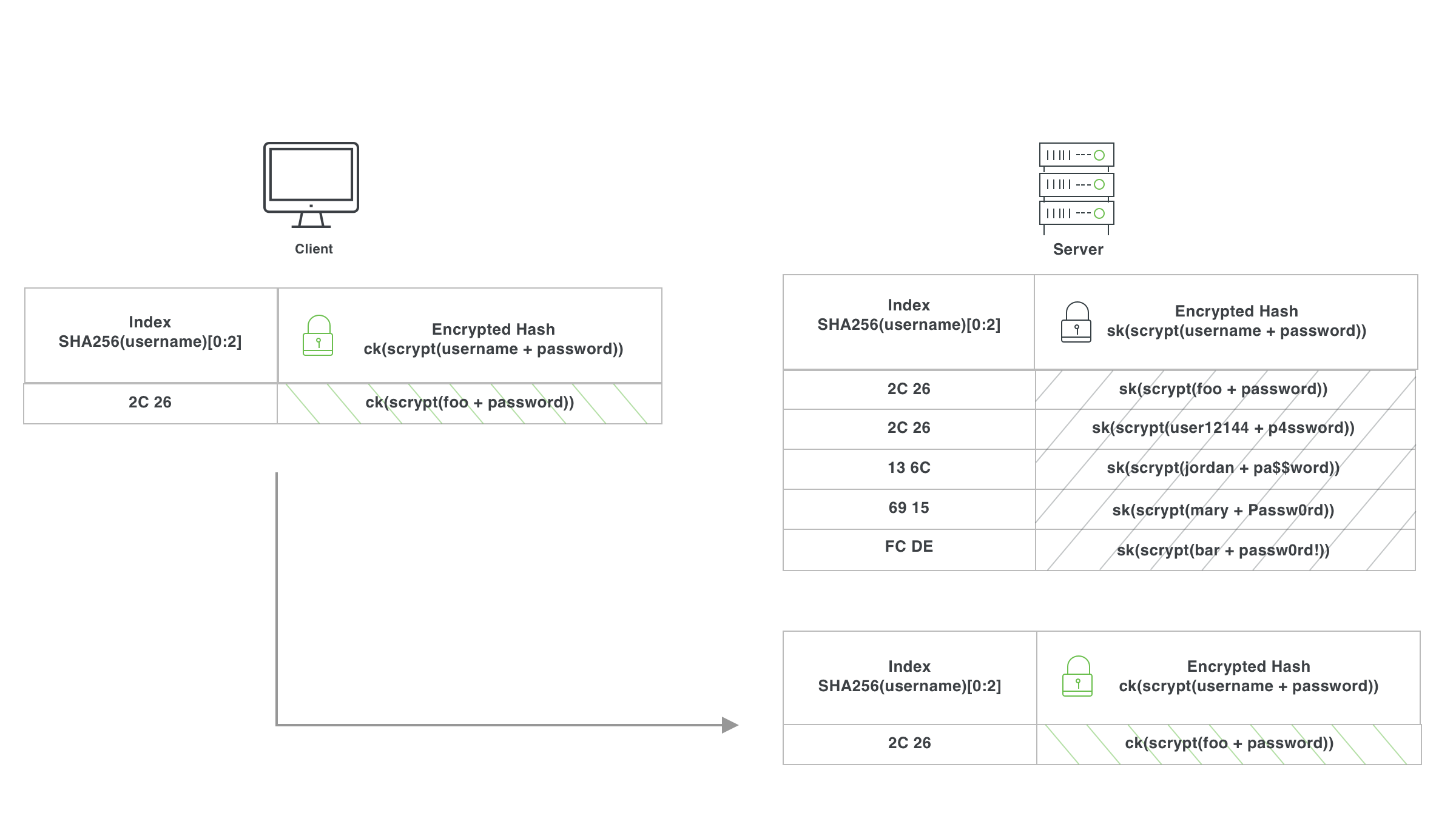
The server then encrypts the already encrypted hash with the server key sk. Separately, the server looks up all of its records that match the provided 2-byte prefix. The server sends the matching records and the double-encrypted hash back to the client.
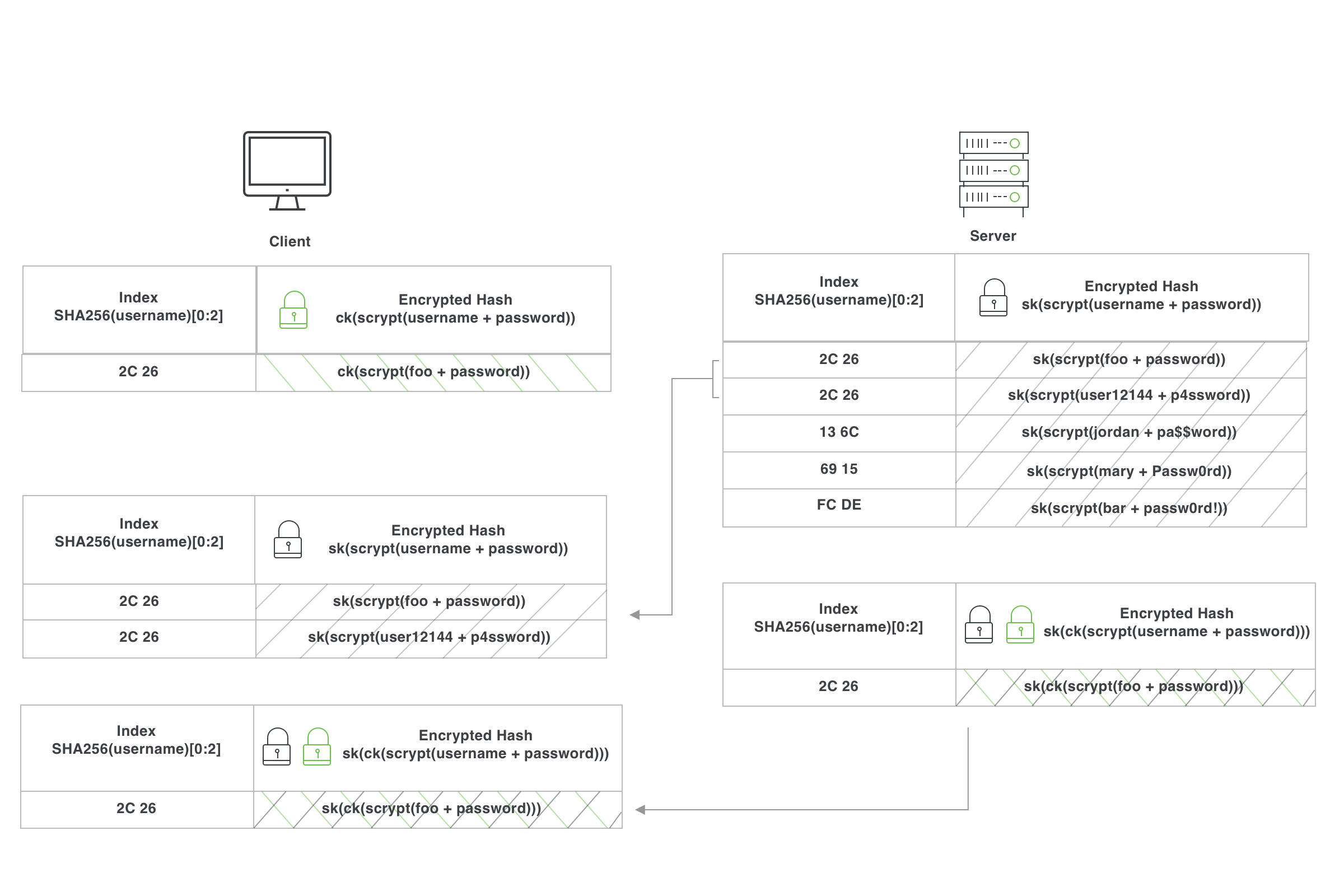
3. Compare the Result
The client now has a list of possibly-matching credential hashes encrypted with the server key sk. It also has its own credential hash encrypted with both ck and sk.
The client then takes this double-encrypted hash and decrypts it with ck. This produces the original client hash encrypted only by sk. This is the magic! By using a commutative cipher (specifically a variant of elliptic curve Diffie–Hellman (ECDH)), we get the following property: ck(sk(hash)) = sk(ck(hash)). This means the client can decrypt its layer of encryption, leaving only the server's.
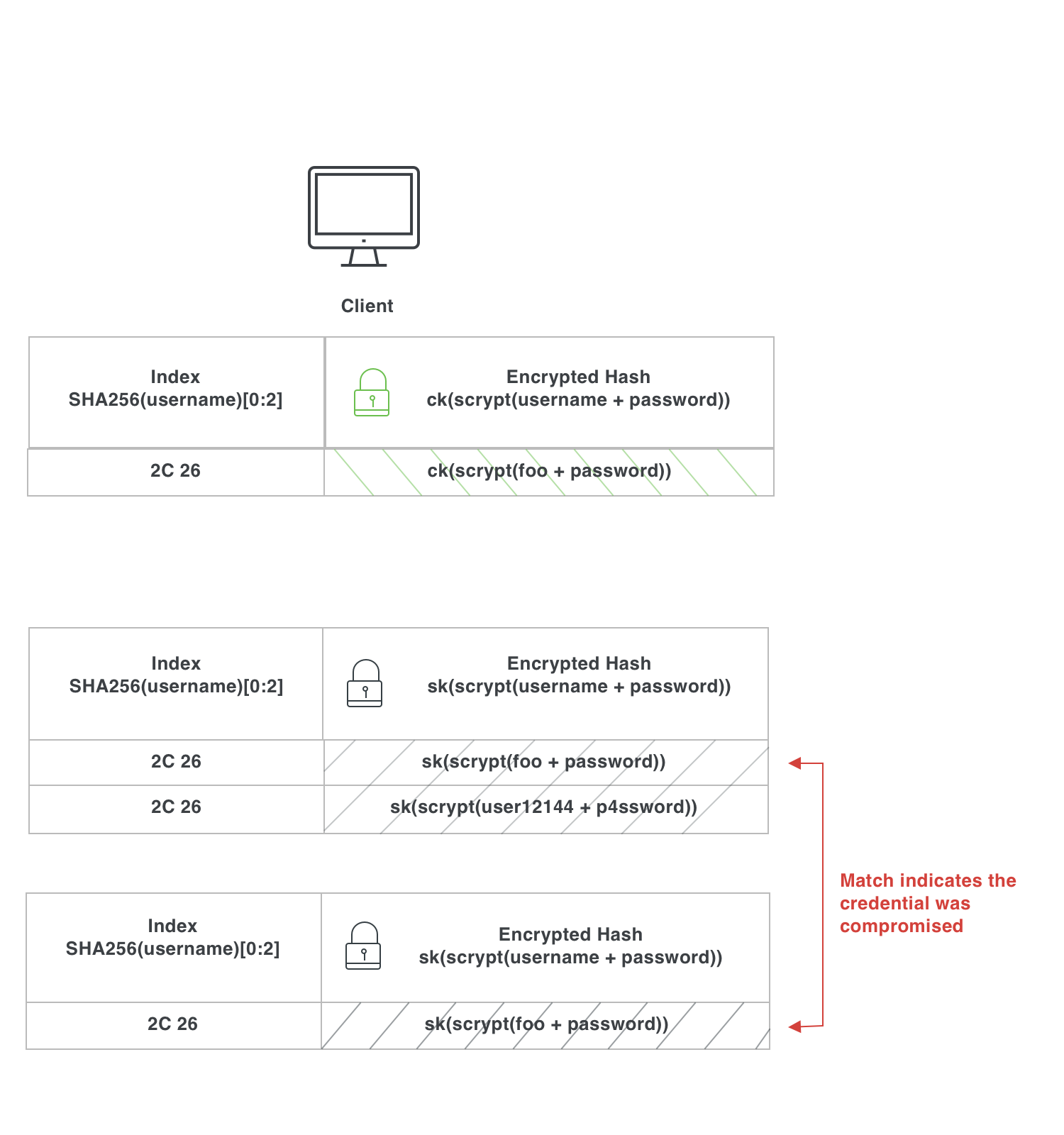
At this point, the client has everything it needs: its own credential encrypted by the server, and a list of possibly matching credential hashes (i.e. credential hashes sharing the same 2-byte “bucket” originally requested), all of which are also encrypted by the server. To know if the credential has been breached, the client just needs to look to see if the encrypted credential appears in this list!
What's so powerful about private set intersection is that since the client provided the credential encrypted using a key it controls, the server never knows what it is. Likewise, since the server provides its potential results encrypted with a key it controls, the client never learns any information about what other credentials are in the provided list of candidates.
For another example of how private set intersection can be used to solve business problems, we recommend reading this infographic from Google.
* The paper initially suggests using 2 bytes from the username + password hash. Later in the paper (section 3.2), they propose a username-only option, which is what is implemented in Chrome and described here.
** The paper initially suggests using Argon2 to construct the username+password hash. At the time of this writing, it appears the Chrome implementation uses scrypt instead.
04. Why This is Important
It's important to note that while this post covers Google's paper, researchers from Cloudflare and Cornell also published a paper in which they independently proposed the same technique being used by Google.
It's encouraging to see the same approach independently published by multiple researchers. It suggests that we might see this protocol becoming the common way to check for compromised credentials. This would allow for clients to get more actionable results while providing better privacy for both the client and the server: a win/win!
And we’re already seeing the benefits from these new approaches. As part of the Password Checkup experiment, Thomas et al. measured how users responded to the breached credential warnings that were displayed. The results showed that 26.1% of users reset their compromised credential after being warned, and 94% of these changes resulted in a new password which was either equally strong to their existing password, or even stronger.
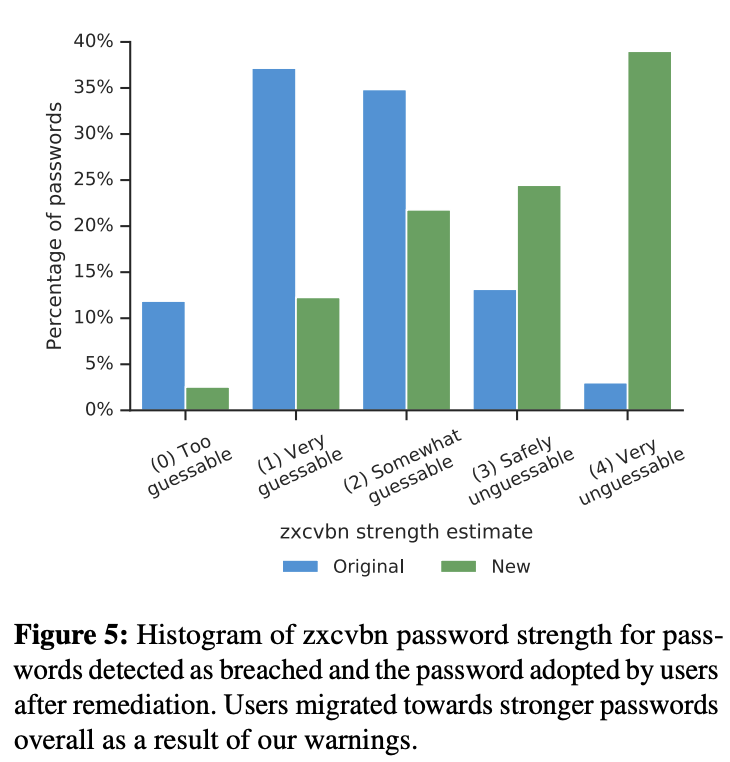
(Image Source: Thomas et al., 2019)
The researchers note that there is still room for improvement. For example, the warning just tells users that they should reset their password, but it doesn’t have the ability to, for example, automate this password reset for them. While automating the full reset flow is challenging, there may be opportunities to improve the user experience if websites were to implement something like this standard for introducing a .well-known/change-password URI. Additionally, Chrome automatically suggests strong passwords for the user, easing the burden of creating and remembering these passwords.
05. Moving Forward
Here at Duo Labs, we're working hard alongside others in the industry to make the passwordless future via open standards such as WebAuthn a reality. WebAuthn solves the problems of passwords, since the credentials created using it can't be weak, re-used, phished, or (usefully) stolen from websites. All with a better user experience!
Unfortunately, the industry isn't there yet.
Until then, it's encouraging to see new and exciting research being done to meet organizations and users where they are, combatting the risks that come along with standard password usage. We look forward to seeing how this new approach for detecting compromised credentials becomes more widely adopted, and seeing organizations benefit as a result.