

Introducing srtgen - Making Automated Transcriptions of Security Content More Widely Accessible
Rich Smith August 4th, 2020 (Last Updated: August 4th, 2020)00. Introduction
Making high quality security information as widely available as possible has been a primary goal of Duo Labs from its inception and this goes not only for our own research but also the wealth of high quality work shared by other groups and individuals. As part of this broader goal, I wanted to share some work done recently that helps make videos of security conference presentations accessible to more people through the efficient transcription of the words spoken and the creation of subtitle files to accompany the video file.
My hope is that by raising the subject for discussion, sharing the approach to the automatic creation of subtitle files, and releasing the tooling built to do all of this as open source software we will better enable the community to easily and cheaply create subtitle files. My intention being that by lowering the barrier to creation of subtitle files we increase the number of them that will be available for security content.
Before we dig into the specifics of the approach that was taken it is worth noting where the inspiration for this work came from. Decipher’s Fahmida Rashid asked a great question in the Duo Labs Slack channel, whether there were subtitle files available for some Blackhat US 2019 conference videos that we were watching as part of a broader research project. To our surprise even though we had spent quite a lot of money on buying licenses for the professionally produced Blackhat videos, none of them came with subtitle files. Looking through our multi-terabyte conference video archive from conferences around the world we found the same to be true for all the conference videos we had: not a single .srt file in sight.
This didn’t seem cool to us so we set out to see what we could do to make security conference videos more accessible to those who are harder of hearing or who just prefer having subtitles while they watch.
01. Problem to Solve
Every year there are thousands of talks given across the many security conferences that take place around the world. While an increasing number of conferences are able to release recordings of the presentations, few if any seemed to also release subtitle files to accompany the videos. The exceptions tend to be talks that are released on a video streaming platform such as YouTube, where there is often the utility to have the service automatically transcribe and show subtitles as the video streams.
The ability to have automated transcription on streamed talks is great but it doesn’t really help to address making non-streamed talks accessible (which is the vast majority) or for the large backlog of presentations that have been made over the years and are scattered across hard disks the world over. We wanted an approach where someone with a security presentation video file would be able to create an accompanying subtitle file quickly, cheaply, and without the need for manual transcription.
More specifically, the requirements we would like the solution to meet are:
- Automated - The approach needs to be automated to the best extent possible, manual transcription is not feasible in most situations
- Accessible - For the user it should be easy to generate subtitles and should not require special knowledge, privileges, or accounts
- Cheap - The cost of generating the subtitle file should be small to negligible
- Timely - The time taken to produce a subtitle file should be small enough that it is reasonable for someone to find a video, transcribe it automatically in a few minutes, and then be able to watch the video with subtitles. We want to aim for minutes, not hours or days
- Accurate ‘enough’ - While perfect transcription would be ideal, even less than perfect transcription can be useful so we may need to trade off accuracy against some of the other requirements above
So let’s jump into how an approach was built that met the above requirements, the decisions that were made along the way, and how you can implement the approach for yourself or your organisation.
02. Approach Taken
The problem of taking audio of spoken words and transcribing them into a written equivalent (aka speech2text) is a hard one but one where there have been significant advances in the last few years. Machine learning based approaches for automated speech transcription have become increasingly available across the main cloud compute platforms and are made readily accessible for use by developers and researchers through simple API’s that hide the complexity of all the hard work that is really going on. If your last experience with automated transcription was shouting at DragonDictate on your trusty Win95 box then it is worth revisiting where the technology has advanced to as it is really impressive.
The approach detailed below uses AWS Transcribe to do all the heavy lifting as AWS was the platform upon which a Labs testbed was already set up, however GCP has a similar offering called simply Cloud Speech-to-Text. The approach below is generic enough that it would be relatively straightforward to use GCP in place of AWS (or any other speech2text solution with an API for that matter) if that is what best meets your needs.
Regardless of the maker of the magic ML speech2text blackbox we choose there are a number of additional steps and data processing that is needed before we have a usable .srt file. Each step will be discussed in more detail below, but at a high level the workflow we are creating looks like:
- Extract the audio from the video file
- Upload that audio to an S3 bucket
- Create & run a new Transcribe job that uses the file uploaded to S3 as it’s source
- Download the completed transcription data
- Generate a valid
.srtformatted file from the transcription data - Watch our conference video in it’s full subtitled glory in any player that supports
.srt
Audio Extraction
While AWS Transcribe can accept video files as input to a job they are large to store and slow to upload so it makes sense to just extract the audio from the video file and upload the smaller file for transcription.
Extracting audio from a video file is a problem that can be solved many ways but given its ubiquity, ffmpeg was chosen. Audio can be extracted from a video file and saved as an .mp3 with with following command:
ffmpeg -y -loglevel error -stats -i <path_to_your_video_file> -f mp3 -ab 48000 -vn <path_to_save_mp3_to>
This command extracts a 48 kbps (-ab 48000) mp3 audio file (-f mp3) from the supplied video file (-i) and writes it to the output file (<audio_output_path>). The video stream will be discarded (-vn), while the extraction is happening status will be displayed (-stats), all prompts will be passed (-y) and output other than errors will be suppressed (-loglevel error).
Why a 48 kbps mp3 for the audio? Isn't that shockingly low quality? Well, yes, quite possibly for music but not so true for just voice. I did quite a bit of analysis around different audio sampling rates and how they affected the accuracy of the AWS Transcribe results and while interesting are beyond the scope of this post. The long story short is that 48 kbps gave the best balance between file size of extracted audio and accuracy of transcription from the analysis I conducted. For a typical 60 minute video the use of an extracted 48 kbps audio stream versus using the full video file reduces the size of data that has to be uploaded and stored from around 500MB to around 15MB. Across a large number of presentations this quickly adds up in terms of reduced storage costs and quicker upload times.
AWS Transcribe
Our use of AWS Transcribe was pretty much a boilerplate use case and so its setup and initialisation was very straightforward. AWS Transcribe uses the concept of jobs for transcription. You create a job with the parameters and source file as you need, and once created, a job can be run. It is worth noting that once a job is running there is no way to cancel it, it will just run to completion and you will be charged for the processing—good to know while you are testing :)
Setting up a transcription job is straightforward enough consisting mainly of naming the job, pointing it to the file you wish to transcribe that is already present in an S3 bucket, the language being spoken, and whether the transcription output should go into an AWS controlled S3 bucket that deletes it after 90 days, or an S3 bucket you control. There are a number of optional parameters that can be set on a job for things like speaker identification (where the transcript has markup showing which person is saying which words), AWS Transcribe has pretty good documentation which we refer you to if you want to understand more about the parameters available.
One interesting aspect of using the API to schedule a job was that there was an additional required parameter named ContentRedaction, in boto3 this parameter takes a dictionary value of:
{'RedactionType': 'PII','RedactionOutput': 'redacted_and_unredacted'}
It seems currently the only redaction type is PII but that may change in future. The value for the RedcationOutput key can be a value of either redacted or redacted_and_unredacted. If redacted is chosen then in addition to a URL to the full transcript there is also an additional value in the response for RedactedTranscriptFileUri where the transcript with the PII removed could be retrieved.
Once scheduled to run the jobs took about 7 or 8 minutes to complete. The Transcribe API has a job status endpoint that can be called and once the job is complete a URL pointing to the transcription file will be supplied in the TranscriptFileUri response parameter. The web interface for Transcribe is pretty basic but also allows you to see details and status of transcription jobs that have been setup:
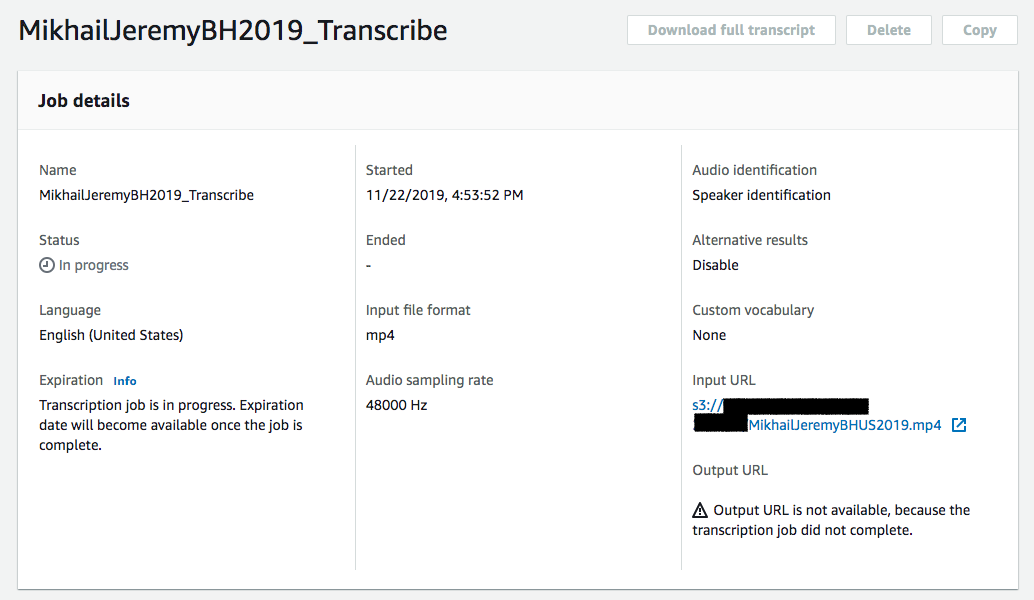
For the 60 min test video we are using, the json file of results from the transcription job is about 1.5MB in size and contains a huge amount of data about the transcription process. Most relevant for our purposes is the transcription text itself, and it was this that is used for the generation of .srt files. In addition to the text there is an abundance of data, in particular about the confidence scores assigned to each transcripted word, as well as the confidence in the alternative words that the model thought the sound could have been.
Now we are in possession of the automatically transcribed speech, we need to take those words and make them into a subtitle file that a video player application can display.
Creation of an .SRT Subtitle File
The way media player applications deal with subtitles for video files (as opposed to DVDs or Blu-rays) is through the use of an additional file that they play alongside the video file to display the words in time with the speech. The most common format that you will find for subtitle files is one called the SubRip file format which uses the .srt file extension.
While I was familiar with using .srt files before this work I didn't know the format and hadn't ever needed to build them from scratch before. It turns out the .srt format itself is very straightforward, but converting to this format from the format we get the AWS Transcribe data in is a bit painful mostly due to how we have to think about timing.
The .srt file format actually comes from the SubRip OSS application. Copying straight from wikipedia:
The SubRip file format is described on the Matroska multimedia container format website as "perhaps the most basic of all subtitle formats."[12] SubRip (SubRip Text) files are named with the extension .srt, and contain formatted lines of plain text in groups separated by a blank line. Subtitles are numbered sequentially, starting at 1. The timecode format used is hours:minutes:seconds,milliseconds with time units fixed to two zero-padded digits and fractions fixed to three zero-padded digits (00:00:00,000). The fractional separator used is the comma, since the program was written in France.
- A numeric counter identifying each sequential subtitle
- The time that the subtitle should appear on the screen, followed by --> and the time it should disappear
- Subtitle text itself on one or more lines
- A blank line containing no text, indicating the end of this subtitle.
Here's an example:
168
00:20:41,150 --> 00:20:45,109
- How did he do that?
- Made him an offer he couldn't refuse.
Timing is a key consideration when thinking about subtitles as you need them displayed in sync with the words being spoken in the video. We also need to make sure we aren’t putting too many words on the screen at once and overwhelming the viewer. In order to be able to create a suitable .srt file we need to walk through each and every word from the produced transcript and bucket them into collections that have an associated timeframe when they will be shown to the viewer.
The json data returned by AWS Transcribe contains an array of data named items in which the precise timing data is present showing the time in which the word was making sound. This timing data makes our task of bucketing words easier and allows us to precisely indicate when they should be displayed. Our bucketing algorithm is very simple: it takes words in groups of 10 and calculates their display window as being the time between which the first word is tagged as starting to be spoken, up until the time the 10th word is finished being spoken. The data needed to be able to do this is returned in the data structure returned from AWS. The other part of being able to bucket groups of words into the timeframe in which they were spoken is that we need to convert the time formats being used as they differ between AWS Transcribe and the .srt’ file format. Code to do this conversion is below:
def getTimeCode(seconds):
t_hund = int(seconds % 1 * 1000)
t_seconds = int(seconds)
t_secs = ((float(t_seconds) / 60) % 1) * 60
t_mins = int(t_seconds / 60)
return str("%02d:%02d:%02d,%03d" % (00, t_mins, int(t_secs), t_hund))
The function above was taken from AWS’s samples github repo and converts the time format returned by AWS Translate which is expressed as a number of seconds, and the timestamp format used by the .srt files which is a string formatted as ‘HH:mm:ss:hhh’. The other code samples in that repository are well worth looking through as they demonstrate the functionality of the Transcribe API more generally as well as containing a lot of examples of useful helpful functions, like the timestamp conversion above.
With all these pieces in place we are now able to iterate through the transcript object returned to use by AWS Transcribe, take the constituent words in groups of 10, and calculate the time each group of words takes to be spoken. Taking all this information and writing it out into the popular .srt format enables us to save a subtitle file that can be played back alongside the original video and overlay the text onto the image.
In terms of cost for using AWS services to do the above a 60 minute conference presentation cost around $1.50 to transcribe, although there are limited amounts of monthly Transcribe usage covered under the AWS Free Tier if you were just looking to experiment without having to incur charges.
Pulling it All Together
So now we understand how we get from having a video file to having a transcription of that video’s audio in .srt format we will bring all the steps together into a few scripts that make things as straightforward as possible.
The code that has been open sourced covers two different modes of operation to support a couple of use cases we could see but the flow is general enough for you to adapt to your specific needs as you see fit.
Standalone Client
The first approach is just a standalone script that automates the steps discussed above, taking in a video file of your choosing and saving an .srt formatted subtitle file. More specifically the steps it takes are:
- Extract audio from video in
.mp3format done viaffmpeg - Upload the audio file to S3
- Setup and run a AWS Transcript job using the S3 file as the job’s input
- Wait for the Transcript job to complete
- Download the Transcript results json blob
- Generate a
.srtfile from the json blob and save file locally
While this works, it does require the user running the script to have an AWS account with the appropriate permissions for S3 and Transcribe which might be fine for us hacker/developer types but is likely not the most useful for someone who just wants to have a subtitle file generated for a conference video. To address this problem a service based approach was developed.
Transcription Service Client
The second approach removes the need for the user having a video transcribed to have any account or related permissions for AWS services, and instead just provides a couple of API endpoints that can be called to mediate the automated transcription process. Chalice is a fantastic Python framework that excels at building serverless endpoints quickly that are based on AWS Lambda and API Gateway and as such is our goto for standing up a Transcription service endpoint.
The basic flow looks very similar to the standalone client flow but there is now a split in where the workload takes place between the client and the (serverless!) service, we will tag each step with whether it takes place on the client or the service and go into more details for each below:
- [Client] Extract audio from video in
.mp3format done viaffmpeg - [Client] Upload the audio file to S3
- [Service] Setup and run a AWS Transcript job using the S3 file as the job’s input
- [Service] Wait for the Transcript job to complete
- [Service] Download the Transcript results json blob
- [Service] Generate a
.srtfile from the json blob - [Client] Download the generated
.srt
Ideally we want all interactions with the AWS infrastructure to come from the service with the client interacting only with the service. Conceptually this is simple with the client extracting the audio locally as before and then uploading the extracted audio to the service for processing, however in practise this pattern only works to an extent due to Chalice’s use of AWS API Gateway that has a maximum payload size limit of 10MB (described as payload size in the API Gateway quotas for configuring and running a REST API section). This means that any video where the extracted audio is larger than 10MB would fail as the upload would be dropped after 10 MB had been uploaded. A 10MB upload limit is not realistic for our use case so we will have to take a slightly modified approach.
A fairly common pattern used to sidestep the 10MB API Gateway payload size limit is an S3 feature called presigned URL’s (boto docs here). In a nutshell for our purposes a presigned S3 URL allows the service to generate an S3 URL with some associated policy and the client uses that URL to upload/download data to/from a predefined S3 bucket. The file uploaded to that S3 bucket is then used as the source file for the AWS transcribe job as before but we have avoided streaming the entire file through the API gateway and so avoided the payload size limits.
The workflow now looks like:
- [Client] Extract audio from video in
.mp3format done viaffmpeg - [Client] Request a URL to upload the audio file to
- [Service] Generate a presigned S3 URL & return that URL to the client
- [Client] Upload the extracted audio file directly to S3 using the returned presigned URL
- [Service] Setup and run a AWS Transcript job using the file upload to the presigned S3 URL as the job’s input
- [Service] Wait for the Transcript job to complete
- [Service] Download the Transcript results json blob
- [Service] Generate a
.srtfile from the json blob - [Client] Download the generated
.srt
With this approach there can be a lightweight transcription client whose only job is to extract audio, request an upload URL, and upload that audio to S3 for processing. The service component is the one that requires AWS permissions and can be configured ahead of time by an admin.
03. Releasing the tool open source
Example code showing an implementation of both approaches has been released here. We hope that this code will help you transcribe videos for yourself and for others and we welcome improvements, additions and bug fixes from the wider community.
If you have a use case for automated transcription that our examples don’t serve well please add to the project if you are able and help others who may have similar needs as you.
04. An Opportunity for our Community
While most of this post has been focussed on the technical approaches to automatically transcribing conference videos there is obviously a huge non-technical part to all of this that is more about how we want to act as a community. Security experts often criticise a lack of awareness and concern about security and privacy issues that increasingly affect the global populace while at the same time doing a less than stellar job of making the information that is out there already accessible to the widest audience. The transcription of security conference presentations is just one small part of making the security information we know is more important now than ever, it is however one that you can have a very direct impact on improving.
If you run a conference that releases video then consider why you’re releasing them, if your intent is to share information that you think is important then make sure that important information can be consumed by the widest number of people in the widest number of ways. Why would you want to do any different? If your conference sells the videos then this is doubly true, your product is not complete if you don’t provide subtitles and you should expect people to pay for an incomplete product. The post above shows how this can be done on a shoestring if needed so the excuse of transcription being cost prohibitive is no longer valid.
If you are someone who gives conference talks that get video’d and released, consider the creation of a subtitle file to accompany the post-talk video as part of the work involved with presenting at a conference and a table stakes requirement for what you ‘leave behind’ just as much as a slide deck or demo code is.
If you are a company who has employees that participate in the security research community make sure you allow enough time after a conference presentation has been given by your employees for a transcription to be generated, manually fixed up, and released—and make sure your employees are clear that you support them in pursuing this work during work hours.
If you are a conference attendee then use your voice to ask the conference directly if transcription is something they are planning on doing for any talks they release. If they are not or were not aware let them know that much of the work can be automated away for minimal cost or offer to help with a transcription effort more directly.
Everyone in the community is in a place to improve the current situation so consider how you might be able to have the most impact to making security information as widely available as possible.
Disrupt. Derisk. Democratise <3