

Open-Sourcing Journal: How Labs Keeps Notes
Jordan Wright October 2nd, 2019 (Last Updated: October 2nd, 2019)00. Introduction
Here at Duo Labs, we’re always working to identify, explore, and publish new security research that moves our industry forward. Whether it’s hunting Twitter bots or reverse-engineering the Apple T2, we aim to publish focused, objective content.
That said, we hold a strong belief that the research journey is just as important as the destination. Behind every one of our reports is a substantial body of research notes that detail every aspect of a project as it’s developed- what we tried, what worked, and what gave us results we didn’t expect. In fact, some of these notes are what make up the Tech Notes section of our blog.
Today, we’re excited to open-source the system we’ve built to keep these research notes called Journal. In this post, we’ll talk about our research process, what led us to build Journal, and why it might be a great fit for your research team.
01. How We Got Here
Before diving into Journal, it’s important to talk a little about how our research process evolved. In the early days of the team, everyone generally kept research notes in whatever format worked best for them. This may have been a wiki, a Google doc, or even a local text file. This made it difficult to discover notes from team members.
As we grew, we recognized the need to centralize our research notes. We started by using Knowledge Repo from Airbnb. Knowledge Repo solved many of our requirements and was a significant improvement in the way we created and shared notes among the team.
While Knowledge Repo was a great start, we found ourselves building tooling on top of it to accommodate our needs. This included a separate client for more streamlined publishing, a rebuilt UI, and more. About 8 months ago, we decided to rethink how we wrote and shared research notes on the team. We made a list of our requirements and designed a system that filled those, and then some. This is Journal.
02. Say Hello to Journal
At its core, Journal is made up of three parts:
- A powerful Hugo theme that supports multiple authors, client-side searching, diagrams, and more
- A command-line client, called
journal, that makes it easy to create and publish new posts, as well as convert Jupyter notebooks and R Markdown into a format that works for Hugo - A CI job that executes every time a new commit is pushed, compiling the site and pushing the result to S3
Hugo is a fast and flexible static site generator which was perfect for our needs. We wanted to minimize the infrastructure we were running, so compiling to a static site and pushing it up to S3 gave us resiliency and speed without having to manage a separate server. We also wanted a generator that supported a content format that was both common and easily accessible to make notetaking as frictionless as possible, and Hugo’s Markdown support fit nicely.
The architecture looks something like this:
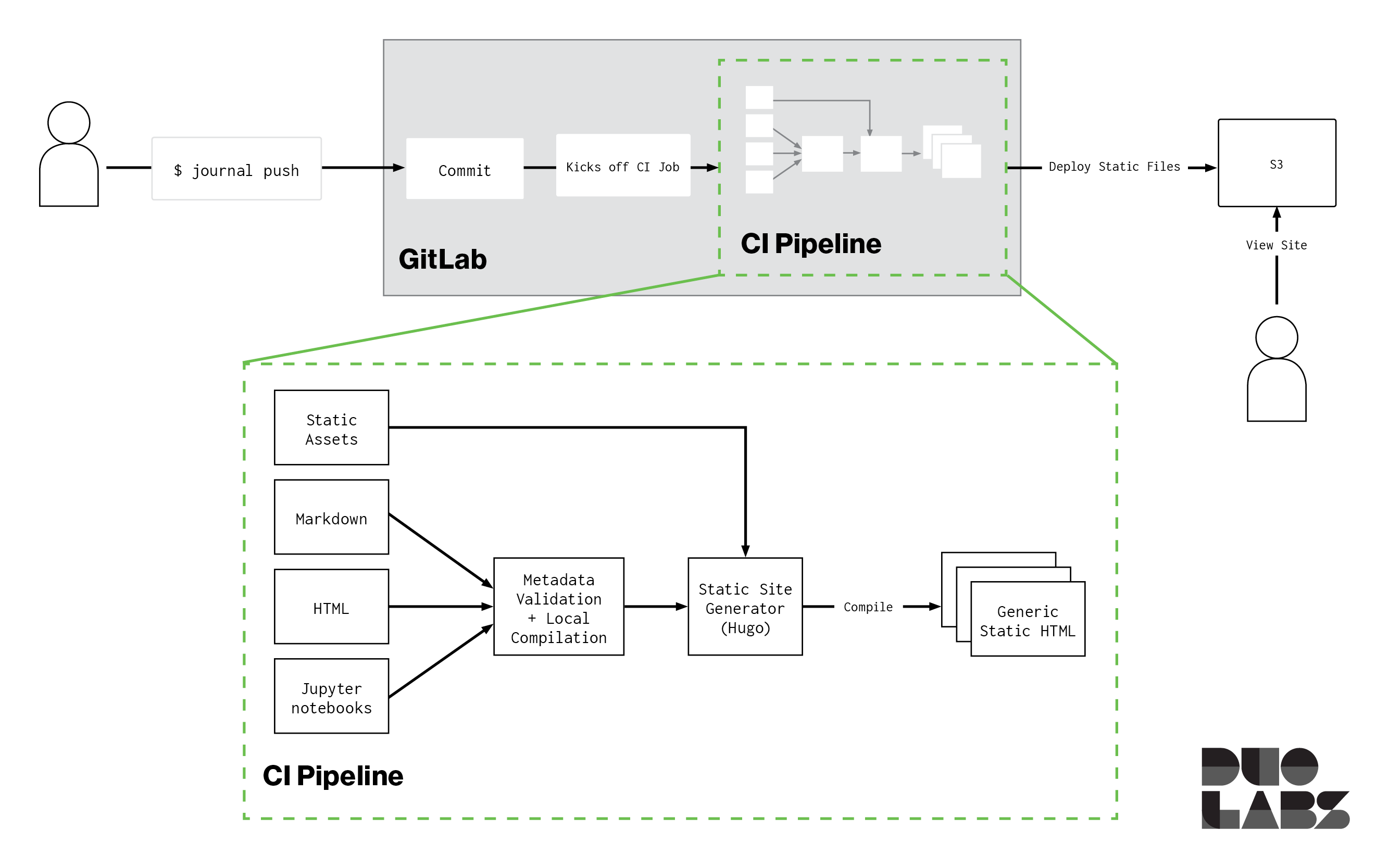
A new entry in Journal starts by creating a new article in Hugo. The journal client makes that easy, creating a new post from a template in the correct folder, then opening the post in your configured editor. We have the ability to leverage Hugo’s previewing capability, giving you the ability to see what your notes will look like as you write them.
When you’re done writing, journal can commit and push the note to the upstream Git repository (usually a simple journal push), kicking off the CI job to build and deploy the Hugo site. This makes the publishing process quick and easy.
The theme we created for Hugo builds on the great work of others such as Casper and Academic to combine powerful features like client-side searching, MermaidJS diagram support, sidenotes, helpful tips, and more with a pleasant reading experience.
03. Moving Forward
Taking good notes is critical to being a great research team. In the 6 months that we’ve used Journal, our team has taken more notes and regularly gives feedback about how enjoyable Journal is to use. We hope that other research teams will be able to leverage and extend Journal to fit their team’s needs.
It’s important to note that this post just scratches the surface of what Journal is capable of. In our next post, we’ll talk about how our data science team is able to leverage Journal as a dataset inventory.
In the meantime, you can find the full Journal documentation on GitHub.
Enjoy!